目录[-]
一个项目实践:通过python爬虫原理,对抖音官方给出的API进行页面访问,并通过python代码实现视频的保存,为方便使用,利用python自带库tkinter编写一个简单的UI界面。
# from tools.dydl import dl
from tkinter import *
import tkinter.simpledialog
import requests, re, json, os
import random
import time
import threading
from tkinter import messagebox
# import tkinter as tk
ua_list = [
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11',
'User-Agent:Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11',
'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.134 Safari/537.36 Edg/103.0.1264.71',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:103.0) Gecko/20100101 Firefox/103.0',
"Opera/9.80(X11;Linuxi686;U;hu)Presto/2.9.168Version/11.50",
"Opera/9.80(X11;Linuxi686;U;ru)Presto/2.8.131Version/11.11",#CSDN copy
"Opera/9.80(X11;Linuxi686;U;es-ES)Presto/2.8.131Version/11.11",
"Mozilla/5.0(WindowsNT5.1;U;en;rv:1.8.1)Gecko/20061208Firefox/5.0Opera11.11",
"Opera/9.80(X11;Linuxx86_64;U;bg)Presto/2.8.131Version/11.10",
"Opera/9.80(WindowsNT6.0;U;en)Presto/2.8.99Version/11.10",
"Opera/9.80(WindowsNT5.1;U;zh-tw)Presto/2.8.131Version/11.10",
"Opera/9.80(WindowsNT6.1;OperaTablet/15165;U;en)Presto/2.8.149Version/11.1",
"Opera/9.80(X11;Linuxx86_64;U;Ubuntu/10.10(maverick);pl)Presto/2.7.62Version/11.01",
"Mozilla/5.0(WindowsNT6.1;WOW64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/65.0.3325.181Safari/537.36",
"Mozilla/5.0(WindowsNT6.1;WOW64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/78.0.3904.97Safari/537.36",
"Mozilla/5.0(WindowsNT6.1;Win64;x64;rv:70.0)Gecko/20100101Firefox/70.0",
"Opera/9.80(X11;Linuxi686;Ubuntu/14.10)Presto/2.12.388Version/12.16",
"Opera/9.80(WindowsNT6.0)Presto/2.12.388Version/12.14",
"Mozilla/5.0(WindowsNT6.0;rv:2.0)Gecko/20100101Firefox/4.0Opera12.14",
"Mozilla/5.0(compatible;MSIE9.0;WindowsNT6.0)Opera12.14",
"Opera/12.80(WindowsNT5.1;U;en)Presto/2.10.289Version/12.02",
"Opera/9.80(WindowsNT6.1;U;es-ES)Presto/2.9.181Version/12.00",
"Opera/9.80(WindowsNT5.1;U;zh-sg)Presto/2.9.181Version/12.00",
"Opera/12.0(WindowsNT5.2;U;en)Presto/22.9.168Version/12.00",
"Opera/12.0(WindowsNT5.1;U;en)Presto/22.9.168Version/12.00",
"Mozilla/5.0(WindowsNT5.1)Gecko/20100101Firefox/14.0Opera/12.0",
"Opera/9.80(WindowsNT6.1;WOW64;U;pt)Presto/2.10.229Version/11.62",
"Opera/9.80(WindowsNT6.0;U;pl)Presto/2.10.229Version/11.62",
"Opera/9.80(Macintosh;IntelMacOSX10.6.8;U;fr)Presto/2.9.168Version/11.52",
"Opera/9.80(Macintosh;IntelMacOSX10.6.8;U;de)Presto/2.9.168Version/11.52",
"Opera/9.80(WindowsNT5.1;U;en)Presto/2.9.168Version/11.51",
"Mozilla/5.0(compatible;MSIE9.0;WindowsNT6.1;de)Opera11.51",
"Opera/9.80(X11;Linuxx86_64;U;fr)Presto/2.9.168Version/11.50",
]
def __fetch(content):
url = re.findall('[a-zA-z]+:\/\/[^\s]*', content)
if len(url) == 0 or 'douyin.com' not in url[0]:
res = 0
else:
res = url[0]
return res
def __video(data,i):
i=str(i)
loc = data.headers.get('Location')
if type(loc) == list:
loc = loc[0]
id = re.findall('(?<=video/).+(?=/\?region)', loc)[0]
api = 'https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/?item_ids=' + id
# headers = {
# 'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1'
# }
headers = {'User-Agent':random.choice(ua_list)} #随机用户请求头
data = requests.get(api, headers = headers)
arr = json.loads(data.text)['item_list'][0]
images = []
image = arr['images']
if image == None:
video = re.findall('href="(.*?)">Found', requests.get(arr['video']['play_addr']['url_list'][0].replace('playwm', 'play'), headers = headers, allow_redirects = False).text)[0]
else:
for i in range(len(image)):
images.append(image[i]['url_list'][0])
# vid = arr['video']['vid']
author = arr['author']['nickname']
avatar = arr['author']['avatar_larger']['url_list'][0]
signature = arr['author']['signature']
title = arr['share_info']['share_title']
music = arr['music']['play_url']['url_list'][0]
# mid = arr['music']['mid']
mtitle = arr['music']['title']
# cover = arr['video']['origin_cover']['url_list'][0]
print('------------------------------')
# i = input('请选择操作:\n1.下载视频/图片\n2.下载背景音乐\n3.查看文案\n4.查看作者信息\n请输入序号:')
path = os.getcwd()
if i == '1':
if images == []:
if not os.path.exists(path + '/video'):
os.mkdir(path + '/video')
video = requests.get(video)
with open(path + '/video/' + title.replace('\n', ' ') + '(' + id + ').mp4', 'wb') as f:
f.write(video.content)
res = '下载视频成功!\n结果保存在' + path + '/video'
else:
if not os.path.exists(path + '/image'):
os.mkdir(path + '/image')
if not os.path.exists(path + '/image/' + id):
os.mkdir(path + '/image/' + id)
for i in range(len(images)):
image = requests.get(images[i])
with open(path + '/image/' + id + '/' + title.replace('\n', ' ') + '(' + str(i) + ').webp', 'wb') as f:
f.write(image.content)
res = '下载图片成功!\n结果保存在' + path + '/image/' + id
elif i == '2':
if not os.path.exists(path + '/music'):
os.mkdir(path + '/music')
music = requests.get(music)
with open(path + '/music/' + mtitle + '(' + id + ').mp3', 'wb') as f:
f.write(music.content)
res = '下载背景音乐成功!\n结果保存在' + path + '/music/'
elif i == '3':
res = signature
elif i == '4':
res = '作者:' + author + '\n头像:' + avatar
else:
res = '指令错误!!!'
return '' + res + '\n------------------------------'
def __author(sec_uid,k):
# global msg
global coninueRun
timesheep_r=k
# all = input('是否全量下载(y/n):')
all ='y'
# for i in range(0,9999):
# try:
# timesheep_r = float(input('批量输入需考虑官方封禁ip,请输入下载每个视频后程序睡眠时间(秒):'))
# except:
# # print("输入非数字,程序终止运行!")
# print("输入非数字,请重新输入!")
# continue
# break
path = os.getcwd()
if not os.path.exists(path + '/author'):
os.mkdir(path + '/author')
max_cursor = 0
total_new = 0
total_old = 0
has_more = True
aweme_list = ''
while has_more:
url = 'https://www.iesdouyin.com/web/api/v2/aweme/post/?sec_uid=' + sec_uid + '&max_cursor=' + str(max_cursor) + '&count=2000'
video_info = json.loads(requests.get(url).text)
aweme_list = video_info['aweme_list']
if all == 'y' or all == '':
has_more = video_info['has_more']
else:
has_more = False
if aweme_list != []:
uid = aweme_list[0]['author']['uid']
# short_id = aweme_list[0]['author']['short_id']
# unique_id = aweme_list[0]['author']['unique_id']
# nickname = aweme_list[0]['author']['nickname']
dl_path = path + '/author/' + uid
if not os.path.exists(dl_path):
os.mkdir(dl_path)
max_cursor = video_info['max_cursor']
f = open(dl_path + '/history.txt', 'a')
h = open(dl_path + '/history.txt')
history = h.readlines()
h.close()
for aweme in aweme_list:
aweme_id = aweme['aweme_id']
video_url = aweme['video']['play_addr']['url_list'][0]
vid = aweme['video']['vid']
desc = aweme['desc']
if aweme_id + '\n' not in history:
if vid == '':
if not os.path.exists(dl_path + '/' + aweme_id):
os.mkdir(dl_path + '/' + aweme_id)
api = 'https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/?item_ids=' + aweme_id
# headers = {
# 'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1'
# }
headers = {'User-Agent':random.choice(ua_list)} #随机用户请求头
data = requests.get(api, headers = headers)
images = json.loads(data.text)['item_list'][0]['images']
for i in range(len(images)):
print('正在下载图片(' + aweme_id + ')(' + str(i + 1) + '/' + str(len(images)) + ')...')
image = requests.get(images[i]['url_list'][0])
with open(dl_path + '/' + aweme_id + '/' + desc.replace('\n', ' ') + '(' + str(i) + ').webp', 'wb') as v:
v.write(image.content)
else:
print('正在下载视频(' + aweme_id + ')...')
msg.insert(END,'正在下载视频(' + aweme_id + ')...')
msg.see("end")
video = requests.get(video_url)
with open(dl_path + '/' + desc.replace('\n', ' ') + '(' + aweme_id + ').mp4', 'wb') as v:
v.write(video.content)
f.write(aweme_id + '\n')
print('下载完成\n------------------------------')
msg.insert(END,'下载完成\n------------------------------')
msg.see("end")
tt=round(random.uniform(timesheep_r,timesheep_r+1),1)#生成1-2之间的浮点数
time.sleep(tt)
# print("已随机睡眠{}~{}秒时间".format(timesheep_r,timesheep_r+1))
print("已随机睡眠{}秒时间".format(tt))
abctime="已随机睡眠{}秒时间\n".format(tt)
msg.insert(END,abctime)
msg.see("end")
total_new += 1
if coninueRun==False:
break
else:
total_old += 1
if has_more == False:
f.close()
break
return '共' + str(total_new + total_old) + '个视频,本次新增下载' + str(total_new) + '个' + '\n------------------------------'+'\n\n\n'
def dl(content,i,j):
if __fetch(content) != 0:
url = __fetch(content)
data = requests.get(url, allow_redirects = False)
sec_uid = re.findall('(?<=sec_uid=)[A-Za-z0-9-_]+', data.text)
if sec_uid == []:
res = __video(data,i)
else:
k=float(j)
res = __author(sec_uid[0],k)
else:
res = '输入链接错误,请重新输入!'
msg.see("end")
return res
# if __name__ == '__main__':
# print(dl('https://v.douyin.com/FAsAnHC/'))
# print(dl('3.05 RxS:/ %抖音热门 %jk护奶裙 %双马尾的小可爱 %二次元 %双肩包 https://v.douyin.com/FD8TKGN/ 复制此链接,打开Dou音搜索,直接观看视频!'))
# print(dl('9- 长按复制此条消息,打开抖音搜索,查看TA的更多作品。 https://v.douyin.com/FAtP3kr/'))
# print(dl('8- 长按复制此条消息,打开抖音搜索,查看TA的更多作品。 https://v.douyin.com/2VDPfJx/'))
# print(dl('8- 长按复制此条消息,打开抖音搜索,查看TA的更多作品。 https://v.douyin.com/FfB1nax/'))
global timesheep_t
global coninueRun
coninueRun=FALSE
timesheep_t=5.0
def aa():
content=text.get("1.0", "end")
if __fetch(content) != 0:
url=__fetch(content)
data=requests.get(url, allow_redirects = False)
sec_uid = re.findall('(?<=sec_uid=)[A-Za-z0-9-_]+', data.text)
if sec_uid == []:
msg.insert(END,dl(content,1,0))
msg.insert(END,"\n")
msg.see("end")
else:
messagebox.showinfo(title='温馨提示', message='输入链接类型错误,请查看是否为主页链接!')
else:
msg.insert(END,'输入链接内容错误,请重新输入!\n')
msg.see("end")
def bb():
global coninueRun
coninueRun=TRUE
content=text.get("1.0", "end")
if __fetch(content) != 0:
url=__fetch(content)
data=requests.get(url, allow_redirects = False)
sec_uid = re.findall('(?<=sec_uid=)[A-Za-z0-9-_]+', data.text)
if sec_uid == []:
messagebox.showinfo(title='温馨提示', message='输入链接类型错误,请查看是否为单个视频链接!')
else:
msg.insert(END,dl(content,1,timesheep_t))
msg.insert(END,"\n")
msg.see("end")
else:
msg.insert(END,'输入链接内容错误,请重新输入!\n')
msg.see("end")
def cc():
content=text.get("1.0", "end")
if __fetch(content) != 0:
url=__fetch(content)
data=requests.get(url, allow_redirects = False)
sec_uid = re.findall('(?<=sec_uid=)[A-Za-z0-9-_]+', data.text)
if sec_uid == []:
msg.insert(END,dl(content,2,0))
msg.insert(END,"\n")
msg.see("end")
else:
messagebox.showinfo(title='温馨提示', message='输入链接类型错误,请查看是否为主页链接!')
else:
msg.insert(END,'输入链接内容错误,请重新输入!\n')
msg.see("end")
def dd():
content=text.get("1.0", "end")
if __fetch(content) != 0:
url=__fetch(content)
data=requests.get(url, allow_redirects = False)
sec_uid = re.findall('(?<=sec_uid=)[A-Za-z0-9-_]+', data.text)
if sec_uid == []:
msg.insert(END,dl(content,3,0))
msg.insert(END,"\n")
msg.see("end")
else:
messagebox.showinfo(title='温馨提示', message='输入链接类型错误,请查看是否为主页链接!')
else:
msg.insert(END,'输入链接内容错误,请重新输入!\n')
msg.see("end")
def ee():
content=text.get("1.0", "end")
if __fetch(content) != 0:
url=__fetch(content)
data=requests.get(url, allow_redirects = False)
sec_uid = re.findall('(?<=sec_uid=)[A-Za-z0-9-_]+', data.text)
if sec_uid == []:
msg.insert(END,dl(content,4,0))
msg.insert(END,"\n")
msg.see("end")
else:
messagebox.showinfo(title='温馨提示', message='输入链接类型错误,请查看是否为主页链接!')
else:
msg.insert(END,'输入链接内容错误,请重新输入!\n')
msg.see("end")
def zz():
text.delete('1.0', END)
zzz=win.clipboard_get()
text.insert(END,zzz)
text.delete('2.0', END)
def ff():
global timesheep_t
timesheep_t=tkinter.simpledialog.askfloat(title= "请输入一个浮点数",prompt = "浮点型变量x:")
msg.insert(END,'批量下载睡眠时间修改为:'+str(timesheep_t)+'\n')
msg.see("end")
def gg():
global coninueRun
coninueRun=False
msg.insert(END,'\n成功触发停止批量下载指令,正在停止中...\n')
msg.see("end")
def thread_it(func, *args):
'''将函数打包进线程'''
# 创建
t = threading.Thread(target=func, args=args)
# 守护 !!!
t.setDaemon(True)
# 启动
t.start()
win=Tk()
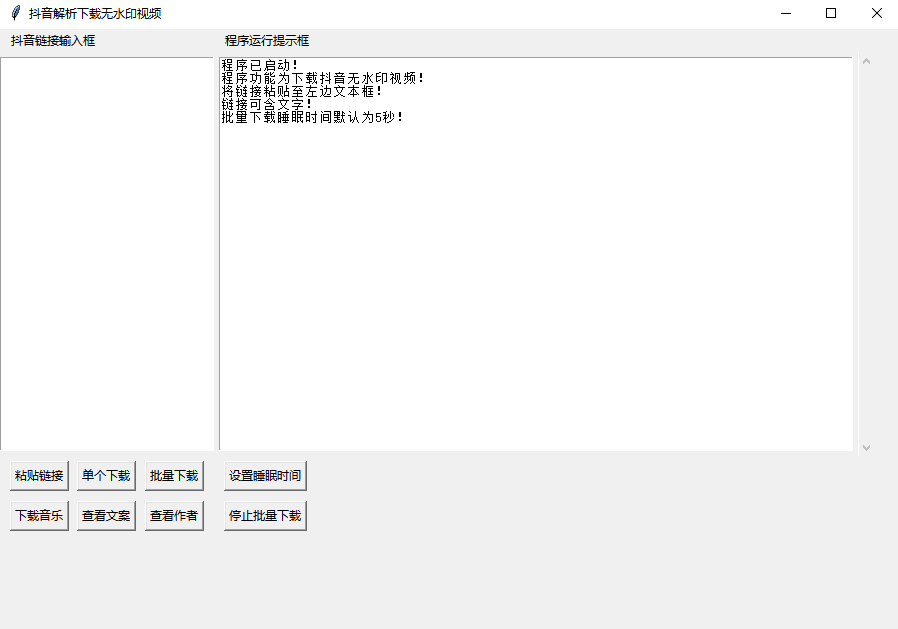
win.geometry('900x600+350+200')
win.title('抖音解析下载无水印视频')
text = Text(win, width=30, heigh=30)
text.grid(row=1, column=0)
label1 = Label(win, text=" 抖音链接输入框").grid(row=0, column=0,sticky="w",)
label2 = Label(win, text=" 程序运行提示框").grid(row=0, column=1,sticky="w",)
z = Button(win, text="粘贴链接",command=zz).grid(row=2, column=0,sticky="w", padx=10, pady=5)
a = Button(win, text="单个下载",command=aa).grid(row=2, column=0, sticky="n", padx=10, pady=5)
# b = Button(win, text="批量下载",command=bb).grid(row=1, column=0, sticky="e", padx=10, pady=5)
b = Button(win, text="批量下载",command=lambda: thread_it(bb)).grid(row=2, column=0, sticky="e", padx=10, pady=5)
c = Button(win, text="下载音乐",command=cc).grid(row=3, column=0, sticky="w", padx=10, pady=5)
d = Button(win, text="查看文案",command=dd).grid(row=3, column=0, sticky="n", padx=10, pady=5)
e = Button(win, text="查看作者",command=ee).grid(row=3, column=0, sticky="e", padx=10, pady=5)
txt="程序已启动!\n程序功能为下载抖音无水印视频!\n将链接粘贴至左边文本框!\n链接可含文字!\n批量下载睡眠时间默认为5秒!\n"
msg=Text(win,width=90,heigh=30,undo=True, autoseparators=False)
msg.grid(row=1, column=1, padx=5, pady=5,sticky="N")
msg.insert(END,txt)
scr=Scrollbar(win,command=msg.yview)
# label2 = Label(win, text=" 睡眠时间:3(请用按钮修改)").grid(row=2, column=1,sticky="w", padx=3, pady=5)
# entry1=Entry(win).grid(row=5, column=0,sticky="w", padx=10)
g = Button(win, text="停止批量下载",command=gg).grid(row=3, column=1, sticky="w", padx=10, pady=5)
f = Button(win, text="设置睡眠时间",command=ff).grid(row=2, column=1, sticky="w", padx=10, pady=5)
# entry1.insert(5)
# entry1.insert(0,"默认文本...")
# entry1.insert(END,'3')
# abcde=entry1.get()
# print(entry1)
scr.grid(row=1, column=3,sticky=S + W + E + N)
msg["yscrollcommand"] =scr.set
scr["command"] = msg.yview
win.mainloop()
# for i in range(0,9999):
# content = input('请输入视频/图片/作者主页链接:')
# print(dl(content))